EXAMPLE 1
Lets generate some random text:
cd /lib/udev/rules.d grep -nir . * | grep SYMLINK | head > /root/text0.txt
SIDENOTE: actually at the time, this text was not random for me. I was doing something with it – in case you were wondering why udev rules output.
SIDENOTE: grep -nir . * is very useful bash command, it shows the output of every text file recusively down (empty lines not included)
Sample output:
# cat /root/text0.txt
10-dm.rules:121:ENV{DM_UDEV_DISABLE_DM_RULES_FLAG}!="1", ENV{DM_NAME}=="?*", SYMLINK+="mapper/$env{DM_NAME}"
11-dm-lvm.rules:47:ENV{DM_VG_NAME}=="?*", ENV{DM_LV_NAME}=="?*", SYMLINK+="$env{DM_VG_NAME}/$env{DM_LV_NAME}", GOTO="lvm_end"
13-dm-disk.rules:17:SYMLINK+="disk/by-id/dm-name-$env{DM_NAME}"
13-dm-disk.rules:18:ENV{DM_UUID}=="?*", SYMLINK+="disk/by-id/dm-uuid-$env{DM_UUID}"
13-dm-disk.rules:25:ENV{ID_FS_USAGE}=="filesystem|other|crypto", ENV{ID_FS_UUID_ENC}=="?*", SYMLINK+="disk/by-uuid/$env{ID_FS_UUID_ENC}"
13-dm-disk.rules:26:ENV{ID_FS_USAGE}=="filesystem|other", ENV{ID_FS_LABEL_ENC}=="?*", SYMLINK+="disk/by-label/$env{ID_FS_LABEL_ENC}"
40-usb_modeswitch.rules:10:KERNEL=="ttyUSB*", ATTRS{bNumConfigurations}=="*", PROGRAM="usb_modeswitch --symlink-name %p %s{idVendor} %s{idProduct} %E{PRODUCT}", SYMLINK+="%c"
50-udev-default.rules:3:SUBSYSTEM=="virtio-ports", KERNEL=="vport*", ATTR{name}=="?*", SYMLINK+="virtio-ports/$attr{name}"
50-udev-default.rules:6:SUBSYSTEM=="rtc", ATTR{hctosys}=="1", SYMLINK+="rtc"
50-udev-default.rules:7:SUBSYSTEM=="rtc", KERNEL=="rtc0", SYMLINK+="rtc", OPTIONS+="link_priority=-100"
I want to select all of the SYMLINK=+”stuff” entries
So I could do this:
cat /root/text0.txt | grep -o 'SYMLINK+=".*"'
NOTE: grep -o , is similar to using grep to extract data. grep -o doesnt show you the full line of what it found. it shows you just what it found. So its a good data extraction tool, thats if you know the regular expression to extract the data with it.
However the output is this, notice it selects more than just SYMLINK and beyond the closing quote mark in SYMLINK , it didnt stop at the correct double quote – instead it goes to the last occurring double quote mark. (so the question is, how do we make it go to the first/next occurring quote mark)
SYMLINK+="mapper/$env{DM_NAME}"
SYMLINK+="$env{DM_VG_NAME}/$env{DM_LV_NAME}", GOTO="lvm_end"
SYMLINK+="disk/by-id/dm-name-$env{DM_NAME}"
SYMLINK+="disk/by-id/dm-uuid-$env{DM_UUID}"
SYMLINK+="disk/by-uuid/$env{ID_FS_UUID_ENC}"
SYMLINK+="disk/by-label/$env{ID_FS_LABEL_ENC}"
SYMLINK+="%c"
SYMLINK+="virtio-ports/$attr{name}"
SYMLINK+="rtc"
SYMLINK+="rtc", OPTIONS+="link_priority=-100"
So we want it to find SYMLINK=+” then everything in between until the next double and then the closing double quote “
* . means any character
* .* means any characters (thats not a new line)
The correct notation would be this:
cat /root/text0.txt | grep -o 'SYMLINK+="[^"]*"'
There we go now we have the correct output (we found SYMLINK+=” and everything until the next appearing double quotation mark” :
SYMLINK+="mapper/$env{DM_NAME}"
SYMLINK+="$env{DM_VG_NAME}/$env{DM_LV_NAME}"
SYMLINK+="disk/by-id/dm-name-$env{DM_NAME}"
SYMLINK+="disk/by-id/dm-uuid-$env{DM_UUID}"
SYMLINK+="disk/by-uuid/$env{ID_FS_UUID_ENC}"
SYMLINK+="disk/by-label/$env{ID_FS_LABEL_ENC}"
SYMLINK+="%c"
SYMLINK+="virtio-ports/$attr{name}"
SYMLINK+="rtc"
SYMLINK+="rtc"
So that says find SYMLINK=+” then everything thats not a double quote, followed by a double quote “
* [^”] means any character thats not a double quote “
* [^”]* means any characters that are not double quotes “
EXAMPLE 2
Read the text1.txt as it states the goal in a weird way.
# cat /root/text1.txt We have some text; here that, looks like this; Looks fun; right? Well it will test first-placed-semicolon finding skills; Lets say we wanted the first semicolon;? can we find it?
cat /root/text1.txt | grep -o "^.*;" # or cat /root/text1.txt | grep -o ".*;"
NOTE: we dont need to specify start of the line ^, answer will be the same, for obvious reasons
So that says find everything from the start of the line, that has any characters up to a semicolon.
The problem is that it will find everything up to the last semicolon in the text
Output will be:
We have some text; here that looks like this; Looks fun; right? Well it will test semicolon finding skills; Lets say we wanted the first semicolon;
To get the correct output do these:
cat /root/text1.txt | grep -o "^[^;]*;" Or: cat /root/text1.txt | grep -o "[^;]*;"
Then we have the correct output (up to the first semicolon):
We have some text;
Looks fun;
Lets say we wanted the first semicolon;
EXTRA:
What if we wanted everything between the first and second semicolon… Then we wouldnt use grep, we would use sed (and use variables, save the 2nd occurance into a variable and make that variable be the output – or select text to the left and right of what we want and make it blank). Or grep in combo with cut -d’;’ -f2 or awk -F’;’ ‘{print $2}’ – the cut will select everything in 2nd field, if you split your text into columns by semicolon delimiters – the awk will split the text by semicolon field/delimiter and print the output of the 2nd column (which is the same thing as doing it with cut). Many ways to do the same thing.
EXAMPLE 3 (added 2015-04-29)
We have some code here (generated by my favorite command grep -nir .* – which simply lists all files recursively in the folder showing their string content and line numbers)
# cat somecode.txt mlab.py:1501:import operator mlab.py:1502:import math mlab.py:2134: import dateutil.parser mlab.py:2135: import datetime mlab.py:2334: try: from numpy.ma import mrecords mlab.py:2449: import dateutil.parser mlab.py:2457: import dateutil.parser mlab.py:2716: from mpl_toolkits.natgrid import _natgrid, __version__ mlab.py:2719: import matplotlib.delaunay as delaunay mlab.py:2720: from matplotlib.delaunay import __version__ mlab.py:3083: import matplotlib.pyplot as plt type1font.py:26:import cStringIO type1font.py:27:import itertools type1font.py:28:import numpy as np type1font.py:29:import re type1font.py:30:import struct units.py:14: import matplotlib.units as units units.py:15: import matplotlib.dates as dates units.py:16: import matplotlib.ticker as ticker units.py:17: import datetime units.py:45:import numpy as np units.py:46:from matplotlib.cbook import iterable, is_numlike, is_string_like widgets.py:12:import numpy as np widgets.py:14:from mlab import dist widgets.py:15:from patches import Circle, Rectangle widgets.py:16:from lines import Line2D widgets.py:17:from transforms import blended_transform_factory widgets.py:828: from matplotlib.widgets import MultiCursor widgets.py:829: from pylab import figure, show, nx widgets.py:1082: import warnings widgets.py:1093: from matplotlib.widgets import RectangleSelector widgets.py:1094: from pylab import *
Lets use the terminals coloring ability, and greps –color to selectively color the first part “filename:linenumber:” so that the part after which is the content of the file is seperated and its easier on the eyes.
cat somecode.txt | grep --color "^.*:" # or this (has same result - its assumed line has started) cat somecode.txt | grep --color ".*:"
It looks like this:
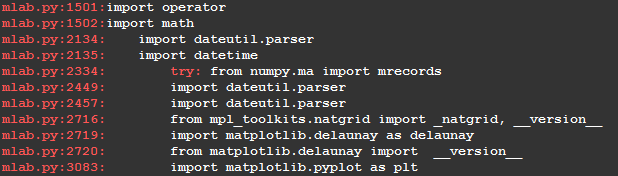
The above will color all of the beginning parts of each line, that look like this: “widgets.py:1082:”.
The problem is that it will also color “mlab.py:2334: try:”, we only want it to color this part “mlab.py:2334:”
Building the solution: If I do this”
cat somecode.txt | grep --color "^[^:]*:" # or this (has same result - its assumed line has started - note that ^ has 2 meanings outside of [] it means start of line, inside [] it means anti-match, it will look for every character except not whats inside [^CHARS] symbols, so it will show Bs,Ds,1,2,3,etc.. but not Cs, or As, or Rs, or S,) cat somecode.txt | grep --color "[^:]*:"
The above says find a line that start with anything except a colon, and find any number of those (so basically select all non-colon characters), until you find a colon, and show all that. (so basically show everything up to the first colon, and show the first colon as well). So it will find & color “NONE-COLON:”
The above will color up to the first colon, so it will color “widgets.py:” part of the line “widgets.py:1094: from pylab import *” but not the full “widgets.py:1094:”, it misses the “1094:” part.
We also want the number (it can be anything though) afterwards up to the next :.
The solution:
# cat somecode.txt | grep --color "^[^:]*:[^:]*:" or of course you can have this variation with the beginning ^ # cat somecode.txt | grep --color "[^:]*:[^:]*:"
The above says find a line that start with anything except a colon, and find any number of those, until you find a colon, and show all that, also keep looking for none colon characters and show them up until the next colon. Meaning show all of the beginning text that starts with a none-colon and goes to a : and then more none-colon text and then one more colon. So it will find & color “NONE-COLON:NONE-COLON:”
Since –color colors what grep finds, and still returns the full line (as grep usually does – sidenote: to stop that behaviour and have grep only show what it has found, and nothing outside of that, so not to display the whole line, use “-o” argument)
What to learn from example3:
(1) you can use the [^C]*C where C is any character as many times as you want. Imagine C is a colon and here is an example of using it 2 times grep –color “[^:]*:[^:]*:”
(2) Well you can use grep -nir . * technique to look thru all files recursively through all folders and you can append the grep trick we just learned to color out the part mentioning the “filename:linenumber:” so that the content stands out (like in the screenshot above)
# To see all text in a folder recursively use this trick: grep -nir . * # . * means show every none empty line (with the first .) and look thru every file with the astericks. # If there are binary files you can skip those with, or else you get a warning in your output grep -nirI . * # you can color your output similar to what we are doing manually with the grep statements above using grep --color -nirI . * # if you want to practice manually coloring the filename:linenumber: you can add this trick on grep -nir . * | grep "^[^:]*:[^:]*:" # and if there are binary files grep -nirI . * | grep "^[^:]*:[^:]*:"