Objective:
Here I will show you how to extract Data From a Site that requires authentication/login with CURL. As an example, we will extract favorite TV shows schedule from next-episode.net
UPDATE 2022-09-07: Additionally, here is a link that shows how to get the latest episodes from next-episode and then download them with iptorrent to your to be picked up by your torrent client: https://gist.github.com/bhbmaster/67bd94386e4c39be3e24778a23480541
Material:
CAUTION: dont use this script to ddos their server. I only use this once per day to get my episode listings.
This example shows how you can login to a website and extract data from any page. So for example the site www.next-episode.com/calendar usually lists the world’s top tv shows & when they are playing this month. Instead of all of those TV shows I want to see what shows that I like are playing this month. next-episode has a feature for registered users to have a “watchlist” then anything on your watchlist shows up on the calendar (and nothing else that you don’t like).
———————————————————————————————————–
Just to let you know there are multiple ways you can login to a site:
1. using webserver authentication scheme by using –username and –password with curl: curl –user USER:PASSWORD https://somesite.com
This type of authentication will look like this:
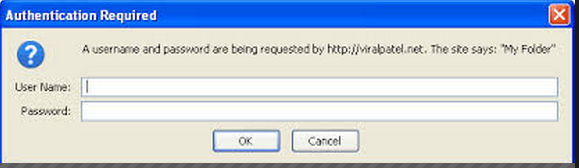
2. by using form data to POST data: curl -c COOKIE.txt –data “user=USER&password=PASSWORD” https://somesite.com
3. by passing the arguments in the URL (this is less secure as the password is visible in the URL so this method is rarely & never used): curl https://somesite.com?user=USER&password=PASSWORD
4. by using API key / bearer token
5. by using OAUTH / OAUTH 2.0
The most common way is to login using method 2 (POSTING via FORMS) and then its method 1 (requires painful & annoying apache/webserver configurations that are not easily accessible by the developers but more by the system administrators), followed by method 3 (least secure)
———————————————————————————————————–
Most websites store cookies when you login, to show that you logged in. Websites that store cookies on your computer can be accessed using this method that I will cover. For more info read: http://stackoverflow.com/questions/12399087/curl-to-access-a-page-that-requires-a-login-from-a-different-page and also http://unix.stackexchange.com/questions/138669/login-site-using-curl
Basically, we are posting (giving information) our authentication information to the webserver using curl, here is another interesting site on posting – it shows all of the different ways you can post to a server: http://superuser.com/questions/149329/what-is-the-curl-command-line-syntax-to-do-a-post-request
Other sites might have an apache login (where you get a popup window where you fill out your username and password), you can fill out the credentials for those using a simpler method: curl -u username:password http://example.com as talked about here: http://stackoverflow.com/questions/2594880/using-curl-with-a-username-and-password
More articles on sending data to a site: http://stackoverflow.com/questions/356705/how-to-send-a-header-using-a-http-request-through-a-curl-call
This script will login to next-episode.net and extract this months calendar for you from the calendar tab. It then saves it to a file and also sends it to a webserver (you can comment out or leave that out). It seds and greps out everything that it needs. Just make sure to edit the username and password variable as described in the comments.
What I first did is I opened up Chrome and I went to https://next-episode.net and then I pressed F12 and went to the Network tab (where you can see the communication between the server and client). You could also see this information with wireshark (for https traffic you would need to be able to decrypt SSL traffic, but for a site that has http you wouldn’t need to decrypt as it will all be human-readable text). Then I put my username and password in the login section and I clicked on login. At that point.
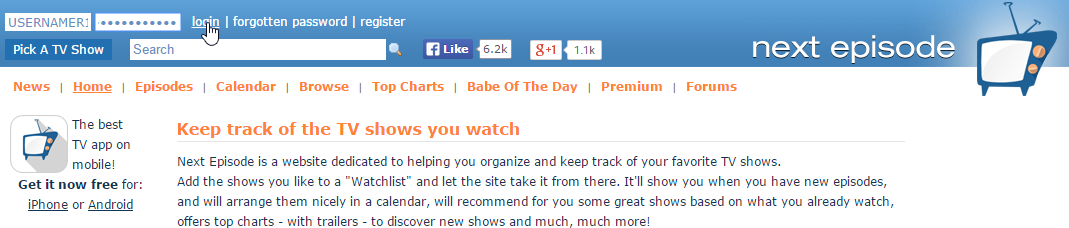
At this point the Network tab gets its list populated. Near the top of the list, you will see the login connection it will be named something along the lines of “login” or “userlogin”, etc… that’s where the user credentials get passed to the server (I oranged out my real username and password):
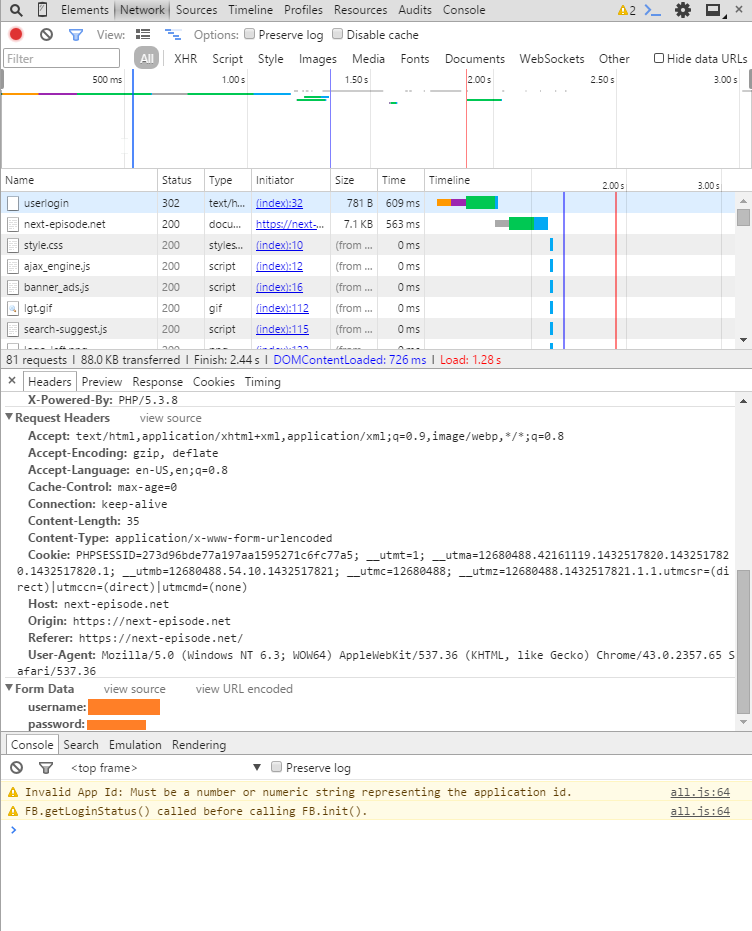
This gives us all of the variables that get passed to the server in order for a connection to be established. We will need to mimic that with curl.
But notice that the form data passes an object called “username” and an object called “password”. That means that we should pass the same objects. In our curls –data (or -d) argument we will pass something along the lines of –data “username=USERNAME123&password=PASSWORD123” or –data “username=USERNAME123” –data “password=PASSWORD123” either way works.
As a sidenote, some logins could be more complicated like this:
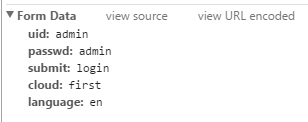
So the command might look like this curl -c /tmp/COOKIE.txt –data “uid=admin&passwd=admin&submit=login&cloud=first&language=en” https://192.168.1.123/login
Anyhow back to next-episode.net example I first tested my command like so:
curl -c mycookie.txt --data "username=USERNAME123&password=PASSWORD123" https://next-episode.net/userlogin
Note that the Request header in the above screenshot mentions an Origin of https://next-episode.net and a referer https://next-epiosode.net, yet we send our data to https://next-episode.net/userlogin. Why do I put https://next-episode.net/userlogin instead of the others? After all I did go to the URL without the /userlogin suffix. If you scroll to the top of the Header output we see this.

And here we see that the data was POSTed to https://next-episode.net/userlogin. So that’s where we have to login.
So when I logged I looked at the Network access tab to find out what items to pass in as form objects via the –data argument, and also what URL I should pass the information to. After that, we ran our command.
curl -c mycookie.txt --data "username=USERNAME123&password=PASSWORD123" https://next-episode.net/userlogin
Next, we can look into the cookie
# cat mycookie.txt # Netscape HTTP Cookie File # http://curl.haxx.se/docs/http-cookies.html # This file was generated by libcurl! Edit at your own risk. next-episode.net FALSE / FALSE 0 PHPSESSID fa351ac4b0fabed7404bc7deaa558f4d next-episode.net FALSE / FALSE 1437704809 next_ep_id_secure 185808 next-episode.net FALSE / FALSE 1437704809 next_ep_user_secure USERNAME123 next-episode.net FALSE / FALSE 1437704809 next_ep_hash_secure %24P%24BIAGSBrvUZ5eSb7q5A1A9mPzKq7Oj5%2d
We can see that the cookie is filled up with good stuff. Now we can use this cookie to look into any page of the website that required login & get the data from that page that a logged-in user would have got. So for example let’s go to the calendar page.
curl -c mycookie.txt -b mycookie.txt https://next-episode.net/calendar
Now that will output all of the output that a logged in user would get. Note that we use -c to write to a cookie and -b to use a cookie. So why did we need to write to a cookie to access the /calendar page? well simply because what if accessing the calendar page writes information to the cookie that is important, I don’t know the mechanics of the site, so it’s best to let the site do with the cookie as it wants. We are basically giving the site write access to the cookie with -c and read access to the cookie with -b.
Now, what if we didn’t get the desired output? In this case that is not the case. However what if on another site we didn’t get the right info? My advice go to Chrome, login to the site with the Network tab recording data & look at the Request Header. Look at all of the different keys and values. Try to match as many as you can. For example, the site might be picky about the UserAgent so you can copy the UserAgent and set it. For example, the useragent when I used chrome was this Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.65 Safari/537.36 so I could try doing this (again I would do this if the first run didnt work – in our case it did so we don’t need to add this next argument to our curl command – but if we had to it would look like this)
-A "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/43.0.2357.65 Safari/537.36"
There are many other Header fields that we can set. Check out the curl man page to see how many you can match. Ideally, if you were able to successfully login with Chrome, then there should be no reason for you cant login with curl – especially if you match all of the Header information that chrome sent. Also as a final tip sometimes there is a third parameter that is sent via -d or –data. So usually it would be like this –data “username=USERNAME123&password=PASSWORD123” and sometimes you might need to do something like this –date “un=USERNAME123&pw=PASSWORD123&php=” (note its not always the case that the username & password parameter are named “username” & “password”, they could be something else such as “un” and “pw” respectively), as seen in this mini example:
# -------------------------------------------------- #
# in this mini example I will show how to use variables for username & password
# imagine some site called somesite.com that holds our running track information times and we want to access that information. But first we need to login to the site "https://www.somesite.com/t/" & then we need to access our track information using "https://www.somesite.com/trackinfo.php?id=12312345". So we will explore how to get the userid (luckily its given to us in the cookie, but it could of also been located on another page that we would have access to after login)
# -------------------------------------------------- #
COOKIE1="mycookie.txt"
UN1="username123"
PW1="password123"
OUTPUT1="mytrackinformation.txt"
# -------------------------------------------------- #
# notice here we have 3 parameters to send to the site (we found these by exploring the Network tab from the Chrome development tools while login). 2 Parameters are the regular username and password (With regular spelling, note some websites might call them "un" and "pw" - however in this case the parameters are named "username" and "password", we would find out all of this thru the Network tab). The 3rd parameters was "php=" and it was set to an empty value. This seems useless but without it the login didnt work. So maybe its part of the websites security algorithms
# -------------------------------------------------- #
curl -c $COOKIE1 --data "username=${UN1}&password=${PW1}&php=" https://www.somesite.com/t/ 2> /dev/null
# -------------------------------------------------- #
# now the next part we need to login to requires the UID. The URL is "https://www.somesite.com/trackinfo.php?id=12312345" & that gets our desired information (in this case its our running track times). In this example the UID is returned to us in the cookie. So what if it wasnt returned in a cookie? Then it would be returned on another site (perhaps a user information site like www.somesite.com/userinfo.php) then we could extract it from there using this method:
# curl -c $COOKIE1 -d $COOKIE1 https//www.somesite.com/userninfo.php -o userinformation.txt
# then we would need to parse userninformation.txt for the desires UID
# luckily in this case the UID is given to us in the cookie.
# so we analyzed mycookie.txt and we saw that the uid was in there and we can extract it with awk/sed/grep
# extract UID (we look for the line that has the word "uid" (we use -w to ask grep to only find "uid stuff" by itself and not "somethinguid stuff" and not "something_uid stuff"). Then we use AWK to print the last column (on the right) which contains our UID
# -------------------------------------------------- #
UID=`cat $COOKIE1 | grep -w uid | awk '{print $NF}'`
# -------------------------------------------------- #
# so now the UID is something like "12321345"
# so now we logged in & we have the UID saved to a variable and now we want to get the the trackinformation
# -------------------------------------------------- #
curl -b $COOKIE1 https://www.somesite.com/trackinfo.php?id=${UIDID} -o $OUTPUT11 2> /dev/null
# -------------------------------------------------- #
# Now all of our output will be saved to OUTPUT1
# you might be thinking we dont need to login to get the track information. We could just do this:
# -------------------------------------------------- #
curl https://www.somesite.com/trackinfo.php?id=${UIDID} -o $OUTPUT11 2> /dev/null
# -------------------------------------------------- #
# however in this case somesite.com requires us to be logged in to get our trackinformation & any other users track information. Its clearly understood that this site allows us to view other users track information by simple changing the id in the URL. However this site doesnt allow unregistered and unauthenticated users to do the same
# -------------------------------------------------- #
# finally we want to logout (we get this URL and what information it needs passed to it from the Chrome Development Tools network tab - we noticed that it didnt need any form data passed to it, it just needed the cookie and the logout - note that it didnt specify it needed the cookie however its a logical fact that you would need the cookie for loging out as the cookie holds a users authentication information)
# -------------------------------------------------- #
curl -c $COOKIE1 -b $COOKIE1 https://www.somesite.com/log-out.php 2> /dev/null
# -------------------------------------------------- #
# the rest of the script - not included here - can be used to parse the output file OUTPUT1="mytrackinformation.txt" for all of the desired information
# -------------------------------------------------- #
One last important point to make is that you should always logout. Open up the chrome development tools and go to network tools. Click on the website’s logout script. And find the corresponding entry for logging out. Then check out the header that was sent for logging out. Usually, it’s quite simple. For next calendar my logout command looked like this:
curl -c ${COOKIE1} -b ${COOKIE1} https://next-episode.net/logout 2>&1 > /dev/null
For another site it could be like this (as seen in the mini example above):
curl -c $COOKIE1 -b $COOKIE1 https://www.somesite.com/log-out.php 2> /dev/null
Below is the next episode script. We add an extra argument -s to the curl commands which simply silents the output on the screen. We don’t want to see any output from curl, other than curl login in and saving the desired website’s raw html data to a file. Then we can use our shell script (using grep/awk/sed) to parse the data for the needed information.
Next Episode Login and Extract Data from Calendar script
Here is the may Next-Episode login and extract FavoriteTV shows for the month’s script
Example output: http://www.infotinks.com/nec/next-episode-nice.txt
DEADLINK: http://www.infotinks.com/nec/nec.txt (if that doesn’t work scroll to the bottom)
WARNING: If the site changes its output layout, I will need to update the script (this had to happen once already) as my awks/sed/greps only work for the time when I tested/edited/wrote the script. So I will have “tested to work on dates” below.
Tested to work on dates:
- 2015-03-09
- 2015-05-24
- 2015-06-15
- latest 2022-09-07 (still works as their site has a proven and tested layout, so no need to change)
The get_nec_info.sh Script:
#!/bin/bash
# FILENAME: get_nec_info.sh
# HOW TO RUN: ./get_nec_info.sh
# WARNING: this script is meant for modification, minimum modification is just adjust UN1, and PW1. The rest depends on if you have certain programs that I use, and if you want to send the results to a webserver you should modify the last ssh line to meet your needs
# BEFORE RUNNING SCRIPT: make sure you have bash version 3 (4 is preferable), also make sure you have curl
# BEFORE RUNNING SCRIPT: edit UN1 and PW1 variables at the top to match your next-episode.net username and password information
# BEFORE RUNNING SCRIPT: make sure you have basename and logger program as well, if not just comment those lines out. Also comment out the bottom section if you dont want to send to a web server (I use ssh to sent to a webserver, you can edit it for whatever)
# -- setting variables -- #
UN1="username123"
PW1="password123"
DIRNAME=$(dirname $(readlink -f "$0"))
COOKIE1="$DIRNAME/xcookie.txt"
OUT1="$DIRNAME/xout1_full-cal-html.txt"
OUT2="$DIRNAME/xout2_days-html.txt"
OUT3="$DIRNAME/xout3_todays-html.txt"
OUT4="$DIRNAME/xout4_final-full-month.txt"
OUT5="$DIRNAME/xout5_final-today.txt"
OUTNICE="$DIRNAME/xout_nice.txt"
# -- loggin -- #
SCRIPTNAME=`basename $0`
logger "${SCRIPTNAME} - getting next_episode.net today and full month info"
# print header
echo "=========== [`date +%D-%T`|`date +%s`s] `basename $0` ==========="
# -- web calls -- #
# login and download the calendar
echo "- login to next-episode.net"
curl -s -c ${COOKIE1} --data "username=${UN1}&password=${PW1}" https://next-episode.net/userlogin 2>&1 > /dev/null || { echo "ERROR: failed at login"; logger "${SCRIPTNAME} - ERROR: failed at login"; exit 1; }
echo "- view calendar & save it to a file"
curl -s -b ${COOKIE1} https://next-episode.net/calendar/ -o ${OUT1} 2>&1 > /dev/null || { echo "ERROR: failed at downloading calendar"; logger "${SCRIPTNAME} - ERROR: failed at downloading calendar"; exit 2; }
echo "- logout out of next-episode.net"
curl -s -c ${COOKIE1} -b ${COOKIE1} https://next-episode.net/logout 2>&1 > /dev/null
rm ${COOKIE1}
# if OUT1 is empty that means we didnt download the script well
RESULTS1LENGTH=$(cat "${OUT1}" | wc -l)
if [ ${RESULTS1LENGTH} -eq 0 ]; then echo "ERROR: downloaded an empty file"; exit -1; fi;
# OUT2 is skipped, used to exist to make OUT1 smaller, so it was less parsing, but in the end less parsing doesnt matter as OUT1 is small enough
# Get today and tommorow day so we can look inbetween those days for which episodes are today
EPOCHNOW=$(date +%s) # get todays epoch sec time
EPOCHTOMMOROW=$((EPOCHNOW+$((60*60*24))))
DAYNUMNOW=$(date --date "@${EPOCHNOW}" +%d | sed 's/^0*//') # removing leading zero with sed
DAYNUMTOMMOROW=$(date --date "@${EPOCHTOMMOROW}" +%d | sed 's/^0*//')
if [ $DAYNUMTOMMOROW -gt $DAYNUMNOW ]; then
echo "- date is NOT End of Month, Looking Between Day $DAYNUMNOW and $DAYNUMTOMMOROW"
cat ${OUT1} | grep -A1000000 "^${DAYNUMNOW}</span> </div>" | grep -B1000000 "^${DAYNUMTOMMOROW}</span> </div>" > ${OUT3} # extracting day
else
echo "- date is end of the Month, Looking Between Day $DAYNUMNOW and $DAYNUMTOMMOROW"
cat ${OUT1} | grep -A1000000 "^${DAYNUMNOW}</span> </div>" | grep -B1000000 "\"afterdayboxes\"" > ${OUT3} # extracting last day
fi
# parse the calendar output for todays and all months output
# shows from all month (adds new line before "a title" tag, greps out dates and a title (so now only episodes and dates with html tags), then looks for title in a title to remove html tag on episode, then looks for day on date tag and surrounds it with ---DAY---
cat ${OUT1} | sed 's/<a title/\\\n<a title/g' | egrep "a title|^[0-9]*</span>\ </div>" | sed 's/^.*a title = "\(.*\)" href.*$/\1/g' | sed 's/^\(.* - [0-9]*x[0-9]*\) -.*$/\1/g;s/^\([0-9]*\)<\/span> <\/div>$/---\1---/g' > ${OUT4}
cat ${OUT3} | sed 's/<a title/\\\n<a title/g' | sed -n 's/^.*a title = "\(.*\)" href.*$/\1/pg' | sed 's/^\(.* - [0-9]*x[0-9]*\) -.*$/\1/g' > ${OUT5}
RESULTS3LENGTH=$(cat "${OUT3}" | wc -l)
RESULTS4LENGTH=$(cat "${OUT4}" | wc -l)
RESULTS5LENGTH=$(cat "${OUT5}" | wc -l)
# save and show all results
echo "- This Months output from the next-episode: ${OUT4}"
echo "cat ${OUT4}"
echo "- Todays output from the next-episode: ${OUT5}"
echo "*********** todays episode list **************"
cat ${OUT5}
echo "**********************************************"
# -- save to nice -- #
echo "Episodes To Watch Today from next-episode.net" > ${OUTNICE}
echo "By: infotinks - Date: `date` - Epoch: `date +%s` s" >> ${OUTNICE}
echo >> ${OUTNICE}
echo "#### --- TODAY: `date +%D` --- ####" >> ${OUTNICE}
cat ${OUT5} >> ${OUTNICE}
echo >> ${OUTNICE}
echo "#### --- WHOLE MONTH --- ###" >> ${OUTNICE}
cat ${OUT4} >> ${OUTNICE}
echo "- deleting extra files (out1, out3, and cookie1)"
rm -f "${OUT1}" "${OUT3}" "${COOKIE1}"
### optional: send to webserver, just fill out USER, SERVER and SSHPORT (default is 22), or use another method to send the file rather than SSH (if using SSH you will need to have your webserver have the public key of this linux box so that the ssh is password less)
echo -n "- sending to webserver: http://www.infotinks.com/nec/nec.txt :"
### optional send method 1 (pick 1 or 2)
cat ${OUTNICE} | ssh root@www.infotinks.com "mkdir -p /var/www/nec 2> /dev/null; cat - > /var/www/nec/nec.txt" > /dev/null 2> /dev/null && { echo ' success!'; SENT="success"; } || { echo ' fail!'; SENT="fail"; }
### optional send method 2 (pick 1 or 2)
# or send it with rsync (sidenote here I supply an ssh key)
# SSH_KEY="/path/to/your/key/file"
# REMOTE_PATH="root@www.infotinks.com:/var/www/nec/nec.txt"
# rsync -av -e "ssh -i $SSH_KEY" "$OUTNICE" "$REMOTE_PATH" && { echo ' success!'; SENT="success"; } || { echo " fail! Error Code $?"; SENT="fail (error $?)"; }
logger "${SCRIPTNAME} - Complete & saved to disk - optional: sent to Webserver: ${SENT}"
### show lines in results ###
echo "- DEBUG: Number of lines in xout1,3,4,5 (2 skipped): ${RESULTS1LENGTH}/${RESULTS3LENGTH}/${RESULTS4LENGTH}/${RESULTS5LENGTH}"
echo "- DEBUG: Number of lines in this Months(xout4) / Today(xout5) Results: ${RESULTS4LENGTH}/${RESULTS5LENGTH}"
NOTE: if someone wants an explanation at what the sed & grep regular expressions are doing, let me know, and Ill append it to the article. Right now I just wanted to post the main meat of it.
Then you can use a crontab to run this once per day:
# get latest episode info from next-episode.net at 6am everyday 0 6 * * * /root/scripts/nec/get_nec_info.sh
Example output (As of 2015-03-09):
Episodes To Watch Today from next-episode.net By: infotinks - Date: Mon Mar 9 19:13:21 PDT 2015 - Epoch: 1425953601 s #### --- TODAY: 03/09/15 --- #### Better Call Saul - 1x06 Scorpion - 1x18 #### --- WHOLE MONTH --- ### ---1--- Secrets & Lies - 1x01 Secrets & Lies - 1x02 The Walking Dead - 5x12 ---2--- Better Call Saul - 1x05 Gotham - 1x18 ---3--- Marvel's Agents of S.H.I.E.L.D. - 2x11 ---4--- The 100 - 2x15 ---5--- Backstrom - 1x07 ---6--- 12 Monkeys - 1x08 Banshee - 3x09 Helix - 2x08 ---7--- ---8--- Secrets & Lies - 1x03 The Walking Dead - 5x13 ---9--- Better Call Saul - 1x06 Scorpion - 1x18 ---10--- Marvel's Agents of S.H.I.E.L.D. - 2x12 ---11--- The 100 - 2x16 ---12--- Backstrom - 1x08 ---13--- 12 Monkeys - 1x09 Banshee - 3x10 Helix - 2x09 ---14--- ---15--- Secrets & Lies - 1x04 The Walking Dead - 5x14 ---16--- Better Call Saul - 1x07 ---17--- Marvel's Agents of S.H.I.E.L.D. - 2x13 The Flash (2014) - 1x15 ---18--- Arrow - 3x16 ---19--- Backstrom - 1x09 ---20--- 12 Monkeys - 1x10 Helix - 2x10 ---21--- ---22--- Secrets & Lies - 1x05 The Walking Dead - 5x15 ---23--- Better Call Saul - 1x08 Scorpion - 1x19 ---24--- Marvel's Agents of S.H.I.E.L.D. - 2x14 The Flash (2014) - 1x16 ---25--- ---26--- ---27--- 12 Monkeys - 1x11 Helix - 2x11 ---28--- ---29--- Secrets & Lies - 1x06 The Walking Dead - 5x16 ---30--- Better Call Saul - 1x09 Scorpion - 1x20 ---31--- Marvel's Agents of S.H.I.E.L.D. - 2x15 The Flash (2014) - 1x17
Example output (As of 2022-09-07):
Episodes To Watch Today from next-episode.net By: infotinks - Date: Wed Sep 7 22:02:03 PDT 2022 - Epoch: 1662613323 s #### --- TODAY: 09/07/22 --- #### #### --- WHOLE MONTH --- ### ---1--- She-Hulk: Attorney at Law - 1x03 ---2--- The Lord of the Rings: The Rings of Power - 1x01 The Lord of the Rings: The Rings of Power - 1x02 See - 3x02 ---3--- ---4--- House of the Dragon - 1x03 ---5--- The Patient - 1x03 ---6--- The Boys - 3xSpecial - A-Train | Turbo Rush Full Commercial ---7--- ---8--- She-Hulk: Attorney at Law - 1x04 Obi-Wan Kenobi - 1xSpecial - Obi-Wan Kenobi: A Jedi's Return ---9--- Cobra Kai - 5x01 Cobra Kai - 5x02 Cobra Kai - 5x03 The Lord of the Rings: The Rings of Power - 1x03 Cobra Kai - 5x04 Cobra Kai - 5x05 Cobra Kai - 5x06 Cobra Kai - 5x07 Cobra Kai - 5x08 Cobra Kai - 5x09 Cobra Kai - 5x10 See - 3x03 ---10--- ---11--- House of the Dragon - 1x04 ---12--- The Patient - 1x04 ---13--- ---14--- The Handmaid's Tale - 5x01 The Handmaid's Tale - 5x02 ---15--- She-Hulk: Attorney at Law - 1x05 ---16--- The Lord of the Rings: The Rings of Power - 1x04 See - 3x04 ---17--- ---18--- House of the Dragon - 1x05 ---19--- The Patient - 1x05 ---20--- ---21--- The Handmaid's Tale - 5x03 Big Sky - 3x01 ---22--- She-Hulk: Attorney at Law - 1x06 ---23--- The Lord of the Rings: The Rings of Power - 1x05 See - 3x05 ---24--- ---25--- House of the Dragon - 1x06 The Rookie - 5x01 ---26--- The Patient - 1x06 ---27--- ---28--- The Handmaid's Tale - 5x04 Big Sky - 3x02 ---29--- She-Hulk: Attorney at Law - 1x07 ---30--- The Lord of the Rings: The Rings of Power - 1x06 See - 3x06
The End
I was nervous about including this detail originally, but “www.somesite.com” is “iptorrent.com”.